
1.要因分析までの振り返り
前回掲載分では、売上に影響を与えている要因を探るため、以下のような事例で要因分析を行いました。
【事例/売上に影響を与えている要因】
渋谷エリア20店舗を統括するコンビニチェーンのマネージャーは、売上が落ち込む原因についてリサーチしています。売上と関連がありそうな要因として、次の4つを考えました。
①接客
②品揃え
③面積
④立地
接客と品揃えについては、調査を実施し、20店舗についてそれぞれ、
5.とても満足している
4.やや満足している
3.どちらもともいえない
2.やや不満
1.かなり不満
と5段階で評価しました。
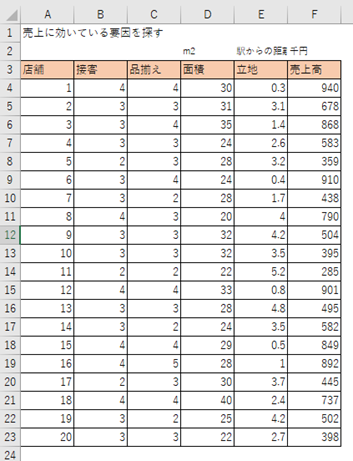
回帰分析の出力結果
回帰分析の下記導出は、前回の記事(#006)を参照してください。
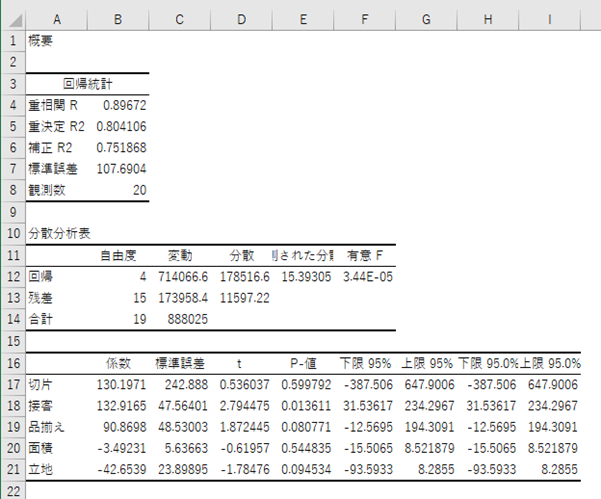
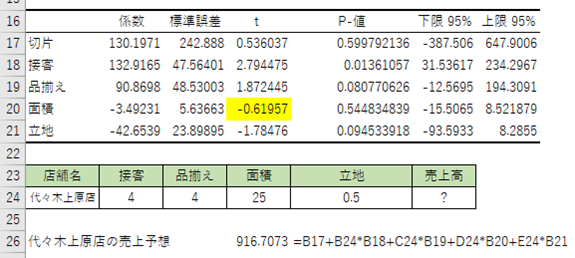
売上高に効いている要因は何か?
影響度の指標であるt値を縦棒グラフで視覚的に捉えました。
影響度の大きさはtの絶対値で判断します。この場合「接客>品揃え>立地>面積」の順で、売上高に影響を与えていることが分かりました。時間とコストは有限です。ある問題があるとき、限られたリソースを改善のためにどこに投入すべきか、優先順位をつける際の目安になります。
ここまでが、前回の振り返りです。
2.変数減少法を使った最適な回帰モデル
ここから新しい問題の設定です。
知りたいことは、作成した回帰式を使って、新たな店舗「代々木上原店」を出店するにあたり、以下のような目標を設定しました。「接客」のスコアは4、「品揃え」のスコアも4、「面積」のスコアは25平米、「立地」は0.5kmという前提条件で新店舗の出店を計画しています。この時の売上を予測したい。これが問題設定です。
①接客
②品揃え
③面積
④立地
すべての説明変数を投入して求めた回帰分析
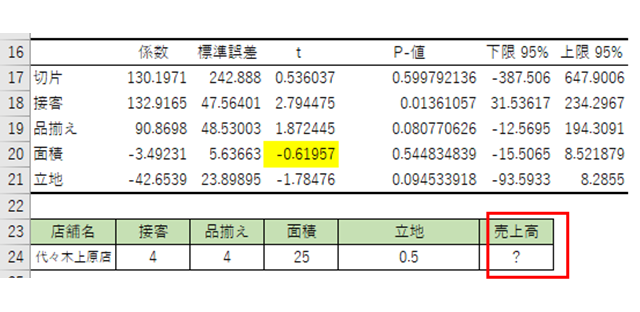
求めたいのは赤枠の売上高!
重回帰式より
y=a+b1x1+b2x2+b3x3…+bnxn
a:切片 b:回帰係数
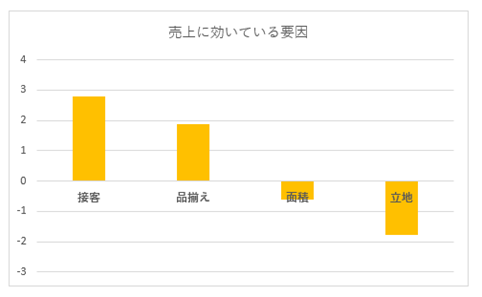
分析結果の表より以下の重回帰式を得ます。
代々木上原店の売上高予測
=130.20+4×132.92+4×90.87+25×-3.50+0.5×-42.65=916.71
と求めることができます。
Excelのセルを参照すると以下のようになります。
以上は、すべての説明変数を使って回帰モデルを作りましたが、本当にこのモデルが最適かどうかは再考する必要があります。
場合によっては、もっと少ない説明変数の方がより精度が高い可能性もあります。
どのような説明変数を採用して回帰モデルを作るのがより精度の高い可能性があります。
このように最適なモデル選択をする手法には変数減少法、変数増加法、変数増減法等様々なアプローチがありますが、今回は、変数減少法を使った最適な回帰モデルの作り方を紹介します。
変数減少法を用いた最適な回帰モデル
①すべての説明変数を投入して一番効いていない説明変数を削除する
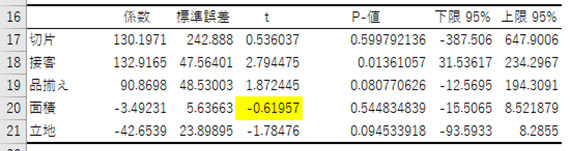
前回の要因分析でも見たように効いている要因は、t値の絶対値で判断します。この場合、0.6と面積が一番効いていないので、面積を除いて、「接客」「品揃え」「立地」の3つの説明変数で改めて回帰分析にかけます。
②影響が一番小さかった「面積」を除いて再度、回帰分析にかける
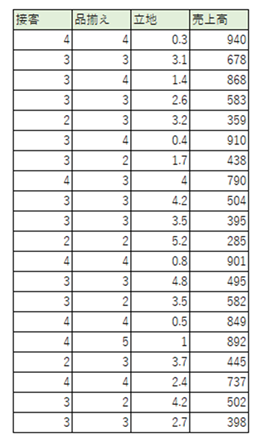
Excelのデータ>データ分析>回帰分析を選んで再度回帰分析にかけます。
出力結果
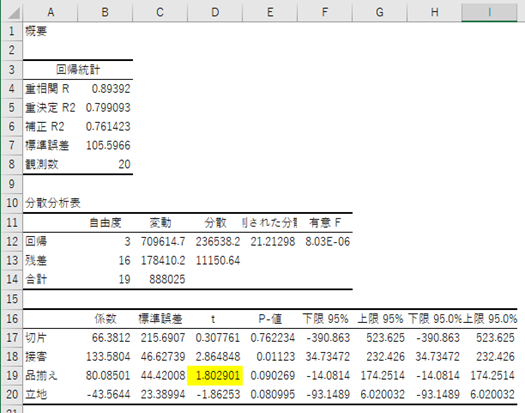
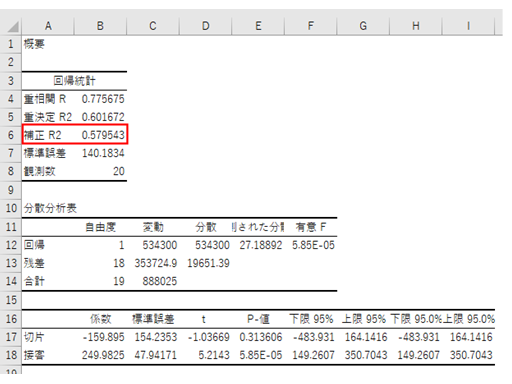
「接客」「品揃え」「立地」の中では、「品揃え」が一番効いていないので、今度は、「品揃え」を除いて再度回帰分析にかけます。
③「接客」と「立地」での回帰分析
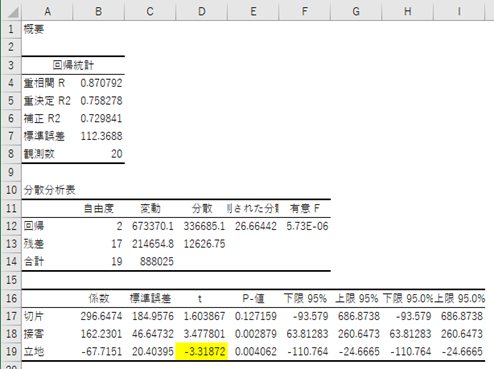
「立地」の方が効いていないので、最後は、「接客」のみで再度、回帰分析にかけます。
④「接客」を使って再度回帰分析
実質、単回帰分析と同様になりますが、以下が出力結果です。

これまでのプロセスで、説明変数の数は、4つの場合、3つの場合、2つの場合と合計、3つの回帰分析を出力しました。次にこの求めた回帰モデルの中で、何を基準として、より精度の高いモデルと判断するかというと、出力結果の一番上のエリアにあります、回帰統計の中の、補正R2を用いて、精度評価を行います。
補正R2について改めて補足します。
補正R2は、重相関係数や重決定係数が持つ変数が多いほど値が大きくなる傾向を修正した数値で、自由度調整済寄与率といいます。重決定係数から次の式で求められます(ここで はデータ数、 kは説明変数の数です)。
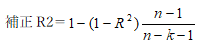
それぞれの補正R2は以下のようになります。
・4変数の場合の補正R2:0.752
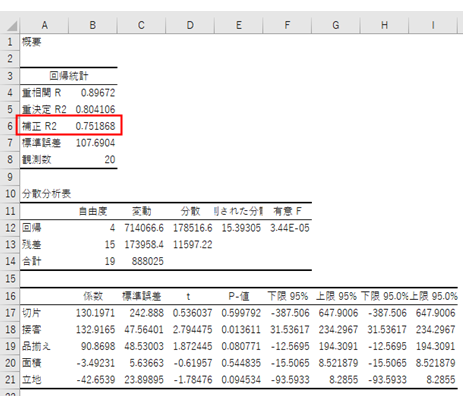
・3変数の場合の補正R2:0.761
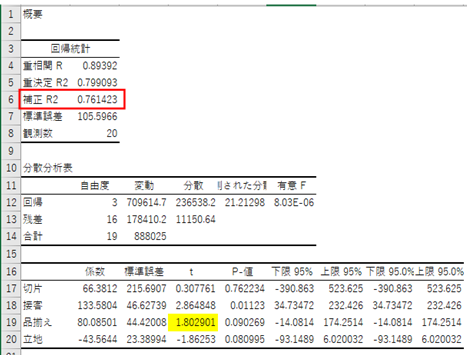
・2変数の場合の補正R2:0.730
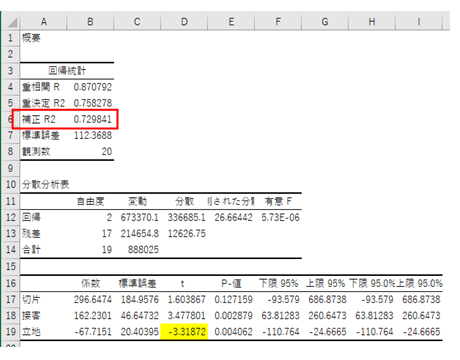
・1変数の場合の補正R2:0.580
一覧にまとめます。
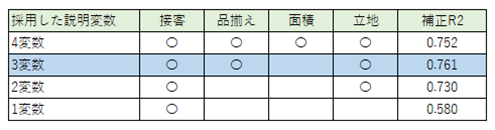
結論として、4つ全部の変数を取り込んで回帰モデルよりも、「接客」「品揃え」「立地」の3変数で回帰モデルを作成した方がより精度の良い予測に使えることとなります。
最後に、最適な回帰モデルを使って、代々木上原店の売上予測を行ってみましょう。
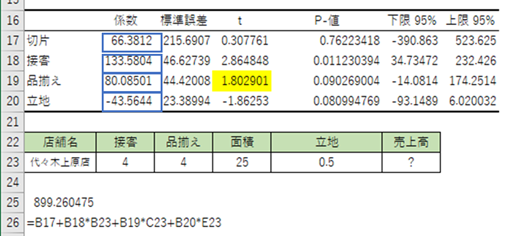
分析結果の表より以下の重回帰式を得ます。
売上高=66.38+133.58×接客+80.09×品揃え-43.56×立地
といった重回帰式を導き出すことができます。新しく店舗を展開する場合など、説明変数に数値を代入することで、おおよその売上高を予測できます。
求めた最適な回帰モデルに代々木上原店の各スコアを代入すると、新しい店舗の売上予測は、899.26(千円)!となります。
来月は、回帰分析シリーズの注意点として、多重共線性という問題を扱いますので乞うご期待ください。
執筆者情報
末吉正成(すえよし・まさなり)
株式会社メディアチャンネル 代表取締役。www.media-ch.com
道具としてのビジネス統計を用いて大学や自治体のWEBコンサルテーションを行う。
著書に『EXCELビジネス統計分析(ビジテク)』(翔泳社)、『EXCELマーケティングリサーチ&データ分析』(翔泳社刊)、『Excelでかんたん統計分析』(オーム社刊)、『事例で学ぶテキストマイニング』(共立出版刊)、『Excelでかんたんデータマイニング』(同友館刊)、『仕事で使える統計解析』(成美堂出版刊)、『見せる統計グラフ』(秀和システム刊)他がある。
ご意見やご感想をお寄せください
データ活用なうでは、今後もより皆さまのデータ利活用に寄与するために、さまざまな専門家の方にその知見を伺い、発信してまいります。
今回の記事がためになった、実務に役に立った方は、ぜひいいね!やシェアをお願いします。
また、筆者の方へご意見・ご感想がありましたら、コメント欄や下記からお問い合わせください。
それでは、次回の記事にもご期待ください!
「ビジネスを成功に導くデータ活用術」連載バックナンバー
今回も前回に引き続き、末吉正成さん「ビジネスを成功に導くデータ活用術」をテーマに執筆いただきました。
データマイニング、データサイエンス、機械学習、AI等々言葉が先行しがちな昨今ですが、時流に流されず、地に足をつけたデータ活用をおこなうための考え方、フレームワーク、そして使い方の注意点などをご紹介いただいております。ぜひご覧下さい。
#006 要因と予測問題を解く①「店舗の売上に影響を与えている原因を探る:重回帰分析」
#007 要因と予測問題を解く②「回帰モデルを使って新しい店舗の売り上げを予測する:重回帰分析」
#EX テキストマイニングはじめの一歩 ~文章データから新たな仮説を導く~


