はじめに
末吉正成さんによる連載「ビジネスを成功に導くデータ活用術」。今回は急遽特別編として、テキストマイニングについてご解説いただきます。

現在、末吉さんによる『データサイエンスセミナー~テキストマイニングで実践する文章データの分析&データ活用術~』が、9/16(木)~9/29(水)までの期間限定で無料配信中です。
セミナーの補足情報として本記事を参考にしていただければと思います。
1. テキストマイニングとは
飲食店等に行った際に、以下のような店舗の顧客満足度のアンケートを見たことはありますでしょうか。

設問によくあるのが、「接客について」「味について」「品揃えについて」「価格について」等を聞いて、回答には満足>やや満足>どちらともいえない>やや不満>不満 の5件法できくものが前段にあり、最後に自由記入欄があるものです。
上図は、一例ですが、自由記入欄のメリットは、設問者が意図しないような気付きを得られる点です。ただし、この貴重な意見も30件程度であれば、目視でだいたいこんなことが書かれてある等、把握することできますが、この記述が、100件、1000件と数が増えてくると人間の読解力だけで内容を把握することは困難になります。
数量データだけでなく、このようなテキスト文書を確率・統計的手法を用いて大量のテキストから有用な情報を引き出す技術の総称をテキストマイニングと呼びます。マイニングとは「採掘する」という意味なので、文字通り、テキストから有用な情報を発見するという意味になります。
テキストマイニングの主な利用分野
・アンケートの自由記述
・Amazonや楽天等の商品レビュー
・twitterなどのSNS分析
・コールセンターのオペレータメモの分析
・特許・論文情報の分析
等々、様々な分野で活用されています。
2. テキストマイニングを支える基盤技術
テキストマイニングを支える基盤技術には、大きく自然言語処理の部分と統計解析の部分によっております。
簡単な処理の流れは以下のようになります。
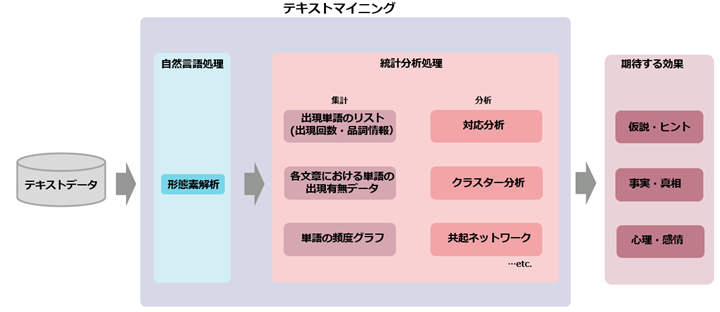
自然言語処理のパートでは、形態素解析という技術が使われます。形態素解析とは、自然言語で書かれた文を意味をもつ最小の単位(=形態素)に分割して品詞を付与する処理のことをいいます。
(品詞を付与しない場合「分かち書き」と呼称します)
具体的には、「こんにちは、私の名前はメディア太郎です。」という文章が与えられた場合、以下のようなユニットに分割します。
こんにちは|私|の|名前|は|メディア|太郎|です|。
となります。それぞれのワードに品詞情報を付与したものが形態素解析となります。
こんにちは コンニチハ こんにちは 感動詞
、 、 、 記号-読点
私 ワタシ 私 名詞-代名詞-一般
の ノ の 助詞-連体化
名前 ナマエ 名前 名詞-一般
は ハ は 助詞-係助詞
メディア メディア メディア 名詞-一般
太郎 タロウ 太郎 名詞-固有名詞-地域-一般
です デス です 助動詞 特殊・デス 基本形
。 。 。 記号-句点
形態素に分けるロジック(形態素解析器)には、Chasen (奈良先端大)、MeCab (工藤拓氏)、JUMAN (京都大学)等々あり、解析器によって分割するポイントが異なることもあります。
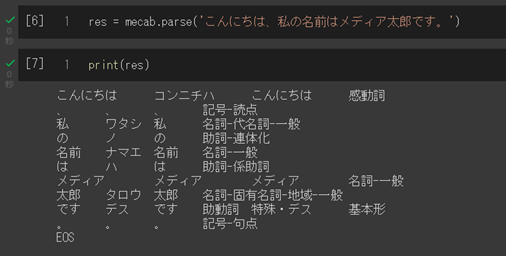
上図は、PythonとMeCabを使った解析結果になります。
統計解析部分では、抽出した語の集計に始まり、対応分析やクラスター分析、共起ネットワークのようないわゆる多変量解析と呼ばれる手法を用いることがあります。
言語の統計解析でどのようなことがわかるのでしょうか?
各手法使い方のオペレーションは本稿に含みませんので、テキストマイニングの使い方をさらに知りたい方は、
「データサイエンスセミナー~テキストマイニングで実践する文章データの分析&データ活用術~」
※9/16(木)~9/29(水)の期間限定無料配信
にご参加ください!
KH Coder(※)ダウンロード
https://khcoder.net/dl3.html
※KH Coderとは…テキスト型データを統計的に分析するためのフリーソフトウェアです。
共起ネットワーク
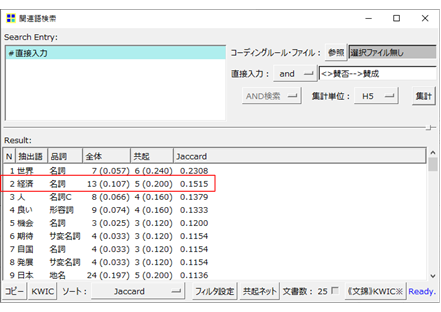
テキストから形態素解析にかけて抽出された語(以下、抽出後)のなかで、単独での抽出後の出現頻度でもどのような語がよく出ているかはわかるのですが、さらに発展すると、どの語とどの語が一緒に使われていたのかという共起関係に注目することで、データの中にどのような話題(主題)が多く出現しているかを考察できます。この関係の強さの尺度として、複数の指標がありますが、Jaccard(ジャカード)係数と呼ばれるものが関係の強さを測ります。
※Jaccard係数の詳細は文末で説明します。

対応分析
対応分析というよりもデータ分析を行ったことがある方であれば、コレスポンデンス分析という呼称の方がなじみがあるかもしれません。テキストを対象にした対応分析の場合、分析にかけるデータは、テキスト本文そのものともう一つのスケールを与える軸を与えてあげる必要があります。
一つの例ですが、以下のようなデータが必要になります。
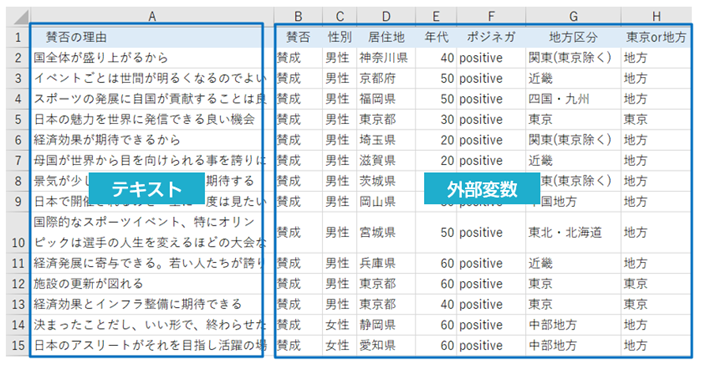
形態素解析にかけた語に対して、それぞれ「賛成」「反対」等のラベルをおなじ座標上でプロットします。
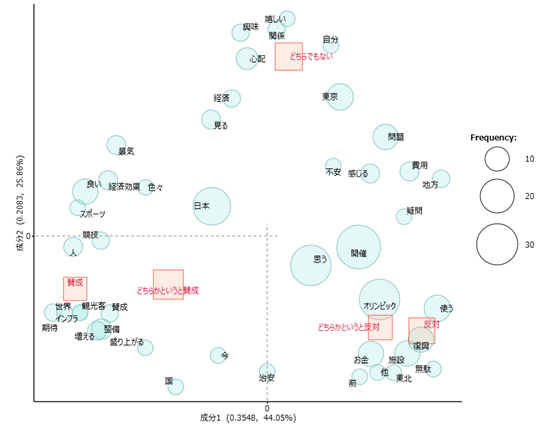
これによって、各ラベル、例えば、賛成というラベルによく出てくる(関連が強い)語にどのようなものがあるか、反対というラベルにはどのような語が多く反応しているかを調べることができます。
対応分析の見方は、原点からの角度と距離に注目します。
原点から見て、各満足度の方向に近く(原点からの角度が近い)ほど、より特徴的な語といえる
逆に、原点付近にプロットされている語は、満足度に関係なく、まんべんなく出現している(=満足度という軸に対してあまり特徴的でない)という意味になります。
少し数学的な解釈を補足すると以下のようになります。
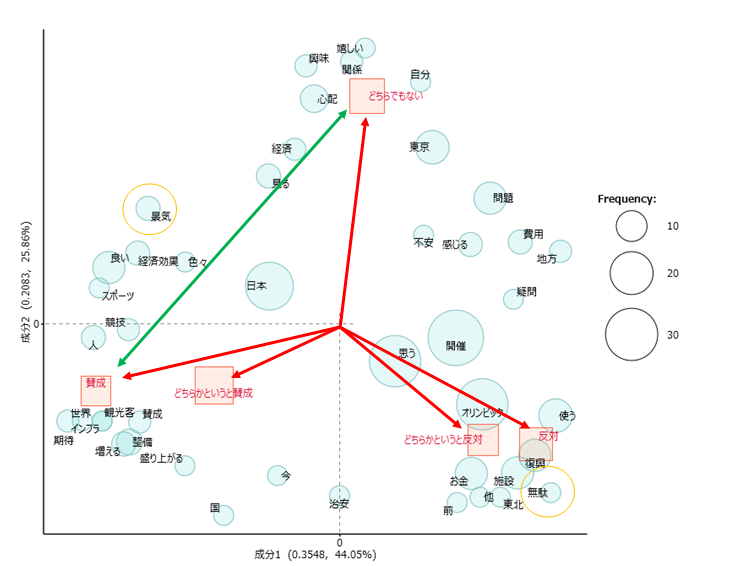
・原点からの方向
角度が大きい=遠い関係
角度が小さい=近い関係
・原点から距離
長い=標準偏差が大きい
短い=標準偏差が小さい
・語の座標も同じ考え方
「景気」と「無駄」は反対方向
3. 技術解析 Jaccard係数
本稿は、テキストマイニングとはどのような手法で、どのようなことができるのかというはじめの一歩をお伝えする趣旨になりますので、1と2で十分なのですが、最後にこれからKH Coderをはじめてみようかなと思われた方に、最初のつまずきポイントである、共起ネットワークなどでよく出てくる語と語の関連性の強さであったJaccard係数の考え方と求め方を説明します
Jaccard係数とは
2つの文書集合に含まれる要素のうちで共通要素の占める割合をさす。よって、Jaccard係数は、0から1の値をとり、値が大きいほど、特徴的な語といえる。
類似度を測るものさしとして、Jaccard係数というものがあります。(他にも、Simpson係数やコサイン距離を求める等、様々なものさしがあります)
式で説明すると
「X」と「Y」という一組のWordの類似性・ 共起性の定義をします。
・「X」と「Y」の単独での出現数を n(X)、n(Y)
・どちらか一方が出現した回数を n(X∪Y)
・両方が同時に出現した回数を n(X∩Y)
上記の前提のもとで、
A)共起頻度
n(X∩Y)
B)Jaccard係数
n(X∩Y) / n(X∪Y)
となります。式で書いてもわかりにくいので、簡単な演算をします。

「経済」という語と「賛成」という外部変数のラベルの間の直線に「.15」と数値があります。これは、0.15のことで、この数値がJaccard係数になります。この0.15は以下のように求めます。
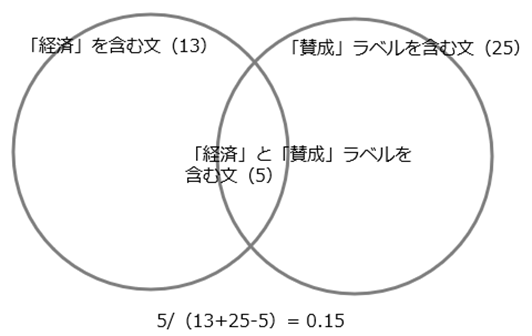
例)「経済」と「賛成」のJaccard係数 0.15の求め方
①左の円:全体=読み込んだテキストすべての段の中の「経済」を含む段数
=13
・段とは、エクセルファイルの場合、1セル内の文が段落になります。
・テキストファイルの場合は、改行(エンター)ごとに1段落になります。
②「賛成」というラベルを含む段
=25
③「経済」と「賛成」ラベルをともに含む段
=5
Jaccard係数は、このともに共起している③が占める割合をさします。
式としては、
5/(13+25-5)= 0.15
となります。
図で書くと以下のようになります。
執筆者情報
末吉正成(すえよし・まさなり)
株式会社メディアチャンネル 代表取締役。www.media-ch.com
道具としてのビジネス統計を用いて大学や自治体のWEBコンサルテーションを行う。
著書に『EXCELビジネス統計分析(ビジテク)』(翔泳社)、『EXCELマーケティングリサーチ&データ分析』(翔泳社刊)、『Excelでかんたん統計分析』(オーム社刊)、『事例で学ぶテキストマイニング』(共立出版刊)、『Excelでかんたんデータマイニング』(同友館刊)、『仕事で使える統計解析』(成美堂出版刊)、『見せる統計グラフ』(秀和システム刊)他がある。
ご意見やご感想をお寄せください
データ活用なうでは、今後もより皆さまのデータ利活用に寄与するために、さまざまな専門家の方にその知見を伺い、発信してまいります。
今回の記事がためになった、実務に役に立った方は、ぜひいいね!やシェアをお願いします。
また、筆者の方へご意見・ご感想がありましたら、コメント欄や下記からお問い合わせください。
それでは、次回の記事にもご期待ください!
「ビジネスを成功に導くデータ活用術」連載バックナンバー
今回も前回に引き続き、末吉正成さん「ビジネスを成功に導くデータ活用術」をテーマに執筆いただきました。
データマイニング、データサイエンス、機械学習、AI等々言葉が先行しがちな昨今ですが、時流に流されず、地に足をつけたデータ活用をおこなうための考え方、フレームワーク、そして使い方の注意点などをご紹介いただいております。ぜひご覧下さい。