
はじめに
データ活用なうでは、より皆さまのデータ利活用に寄与するために、さまざまな専門家の方にその知見を伺い、発信してまいります。
データサイエンティストで株式会社メディアチャンネル 代表取締役の末吉正成(すえよし・まさなり)さんに、今回より毎月1回「ビジネスを成功に導くデータ活用術」をテーマに執筆いただきます。
データマイニング、データサイエンス、機械学習、AI等々言葉が先行しがちな昨今ですが、時流に流されず、地に足をつけたデータ活用をおこなうための考え方、フレームワーク、そして使い方の注意点などをご紹介いただきます。ぜひご覧下さい。

データを情報、そして知恵へと昇華させる必要性
データ分析というとイコール機械学習というイメージが多いかもしれません。データサイエンスを専門とするデータサイエンティストを部署で抱える会社ほど、営業部、マーケティング部、情報管理部等縦割りのリスクが増えてきます。
マーケティング部→データ分析組部署
例:直近〇か月でリピート購入していない関東圏の居住者のリストを抽出して!
データ分析部署は、抽出理由(なぜそのデータが必要なのか)をよく理解しないまま、オペレータ的に購買データベースからリストを抽出する。
これでは真に強い組織を作ることは難しいです。データを支給されるとまずPython等の機械学習ライブラリに手を出す前に、なぜその分析が必要なのか、何を知りたくて解析を行うのか、解析の結果、どのようなアクションにつなげたいのか、この一連の解析設計が事前にできていないと、いきあたりばったりの調査のための調査になります。
目指すべき場所に向かうには、データを情報に変え、さらに会社全体で問題解決に役に立つような知識・知恵までに昇華する必要があります。

データを真に意味のあるKnowledgeにまで変換するために有効なフレームワークとして、本稿では、CRISP-DM(クリスプディーエム)という手法をご紹介します。
CRISP-DMはどのようなフレームワークなのか
CRISP-DM とは、Cross-Industry Standard Process for Data Mining の略で、意訳すると、特に業種を限定しなくてもデータマイニングのプロセスのフォーマットを作ってみました的な感じです。
データ分析を積極的に行っている会社(SPSS、NCR、ダイムラークライスラー、OHRA等)がメンバーとなっているコンソーシアムにて開発されたデータマイニングのための方法論を規定したものになります。一度は、以下のような図を見たことがあるかもしれません。
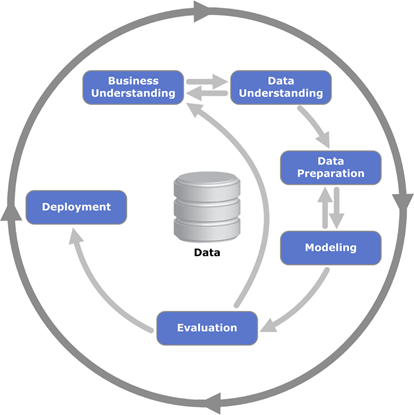
図からもわかるように、CRISP-DMでは、以下、6つのプロセスが連関しながらまわっています。

①ビジネス理解(Business Understanding)
②データ理解(Data Understanding)
③データ準備(Data Preparation)
④モデル作成(Modeling)
⑤評価(Evaluation)
⑥展開(Deployment)
それでは、一つ一つ簡単に見ていきましょう。
ビジネス理解(Business Understanding)
データ分析とビジネス理解は一見、関係なさそうですが、データをもらっていきなり解析にかける前に、
・そもそも何を解決するためにデータを見るのか、集めてくるのか
・何をもって分析プロジェクトの成功とするのか
を明確にすることが重要です。
会社によって、まちまちだと思いますが、私が個人的に気を付けているのは、その分析結果が課題解決するアクションを促すものなのかを意識しております。
データ理解(Data Understanding)
これは例えば、ECサイトのレコメンドエンジンの精度が悪いという課題があった場合、そもそも手持ちデータの型として、購買データ、併売データ、顧客属性データ等の各データベースが、顧客IDのようなもので、データを串刺しで見ることができるのかなどのように、何を解決するための分析かという目標が設定できても、データの型、質、特徴によって、解析に使えないものでは意味がありません。
手持ちのデータが、解析の目標、設計に使えるものなのかどうかの見極めが大切になります。
データ準備(Data Preparation)
より良い結果を産むためにデータの前加工をするプロセスがここになります。
書籍やデータ分析のセミナーでは、私も読書や参加者の方にわかりやすいようにデータをきれいに加工し、よりきれいな解が求まるようにするのですが、実務のデータは決してきれいな状態ではありません。
データに値が入っていない状態(欠損値)、性別や血液型のようにそのままでは分析にかけることができないので、0、1データに変換する作業(ダミー変数化)、データの中で、極端に離れたところにある値(外れ値)がある場合の処理、さらに私が良く扱うWEBサイトのログデータであれば、資料請求に反応した場合は1ですが、それ以外のページをほぼ見ていなければ、ログデータのほとんどが0でたまに1がでるようなデータ(疎のデータまたはスパースデータと呼ばれます)など様々なデータが存在しております。
この工程は、分析業務でいうところの「前処理」と呼ばれるものに該当します。経験上、データ分析の作業の6から7割はこの前処理に費やされます。
モデル作成(Modeling)
ここまできて、Pythonを使う方であれば、おなじみのscikit-learnなどを使って、実際の機械学習のモデル作成になります。
機械学習のモデルの一つ一つの解説をする分量はありませんが、以下のようなモデルのあてはめ方があります。
解こうとしている問題が
・分類問題なのか(Yes,No, 合格、不合格などの2値を分類するタスクなのか)
・回帰問題なのか(売上金額、数量を予測するタスクなのか)
・時系列の問題をとくタスクなのか
等、ある程度の型があります。統計解析に特化しているRではあれば、一つ一つのモデル作成に対応するライブラリが存在しますが、Pythonの場合、前述のscikit-learnでおおよそ解くことができます。
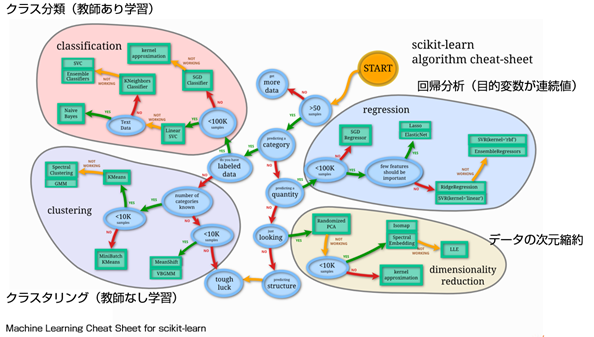
どのようなデータの型、特徴の場合、どのモデルが使えるのかの簡単なチートシートが、scikit-learnのサイトにありますので、ご参照ください。
モデル評価(Evaluation)
ロジスティック回帰のような分類のタスクであれば、適合率(モデル式で作った予測値と実際の実測値がどの程度、分類を実現できているかのあてはまり度をみます)などを見たり、回帰のタスクであれば、決定係数や誤差を平均化して精度をはかるRMSE(平均平方二乗誤差)やMSE(平均二乗誤差)などを用いてモデルを評価します。
展開(Deployment)
英語のDeploy(デプロイ)は開発に携わっている方ならしっくりする用語ですが、作成したプログラムをアップして使える状態にすることを指します。
これを分析界にあてはめると、マーケティング部や営業部なども取り込み、解析結果から実際にアクションに落とし込んで反応をみるといったアプローチになります。例えば、定期購読の解約が落ちた要因を探る分析を行い、対応策を講じて反応をみるといったアクションになります。
最も大切なアプローチは解析設計を最初に立てること
今回は、解析プロセスの一つとして、CRISP-DMを紹介しました。これ以外にも、ニュージーランドをスタートに日本の総務省統計局でもよく紹介されているPPDACという手法もあります。
いずれにせよ、手法も名称を覚え、プロセス通りに実行しなくてはいけないといったたぐいのものではありません。大切なことは、いきなり解析に入るのではなく、まず問題・課題を設定し、解析設計をしっかり立ててから分析にとりかかり、結果はアクションにつながることを意識する。この流れを一番根っこのところで意識できれば、今後のみなさまのデータ活用がより有意義なものになるかと思います。
関連リンク
PPDAC 総務省統計局データスタート「PPDACサイクルとは?」
http://www.stat.go.jp/dstart/point/seminar1/01.html
総務省統計局 なるほど統計学園高等部
https://www.stat.go.jp/koukou/howto/process/index.html
PPDAC(大元のニュージーランドの情報)
CensusAtSchool NZ (2013)Data DetectivePoster−CensusAtSchool New Zealand,
http://new.censusatschool.org.nz/resource/data-detective-poster/
執筆者情報
末吉正成(すえよし・まさなり)
株式会社メディアチャンネル 代表取締役。www.media-ch.com
道具としてのビジネス統計を用いて大学や自治体のWEBコンサルテーションを行う。
著書に『EXCELビジネス統計分析(ビジテク)』(翔泳社)、『EXCELマーケティングリサーチ&データ分析』(翔泳社刊)、『Excelでかんたん統計分析』(オーム社刊)、『事例で学ぶテキストマイニング』(共立出版刊)、『Excelでかんたんデータマイニング』(同友館刊)、『仕事で使える統計解析』(成美堂出版刊)、『見せる統計グラフ』(秀和システム刊)他がある。
ご意見やご感想をお寄せください
データ活用なうでは、今後もより皆さまのデータ利活用に寄与するために、さまざまな専門家の方にその知見を伺い、発信してまいります。
今回の記事がためになった、実務に役に立った方は、ぜひいいね!やシェアをお願いします。
また、筆者の方へご意見・ご感想がありましたら、コメント欄や下記からお問い合わせください。
それでは、次回の記事にもご期待ください!






